MBE opties (Opties | Engine)
Deze opties bepalen een aantal belangrijke parameters voor de sturing van de MBE:
- De vertreksituatie voor de geselecteerde opdrachten: de opdrachten die geselecteerd zijn, kunnen al een plaats hebben in het rooster. Opties zullen bepalen wat we met die informatie moeten doen: gebruiken of niet en, indien wel, is de vraag op welke manier.
- Wat moet er gedaan worden met opdrachten die niet geselecteerd werden, maar die al wel een plaats in het rooster hadden? Moeten we die opdrachten negeren in de MBE of moeten we ze dan toch meenemen en op welke manier moet de informatie over hun huidige plaats in het rooster gebruikt worden?
- Moet de MBE voor het effectieve zoeken naar een oplossing eerst een analyse doen van de complexiteit van de opdrachten? Indien zo, is de vraag hoever hij moet gaan in die analyse. De informatie die uit die analyse komt, wordt dan gebruikt in het effectieve zoeken naar een oplossing. Dit gaat meestal helpen om sneller tot een oplossing te komen.
- Welke methode moet de MBE gebruiken om naar een oplossing te zoeken? Er werden 2 methodes voorzien.
- Tenslotte kan men nog vragen om een diagnosebestand aan te laten maken waarin de MBE een overzicht geeft van de opdrachten die geplaatst moeten worden en onder meer een overzicht geeft van de door de MBE bepaalde complexiteit van elke resource.
Bepaalde combinaties van opties zijn niet mogelijk. Dit zal ook uitgelegd worden. Mondriaan geeft ook een waarschuwing wanneer onmogelijke combinaties opgegeven worden.
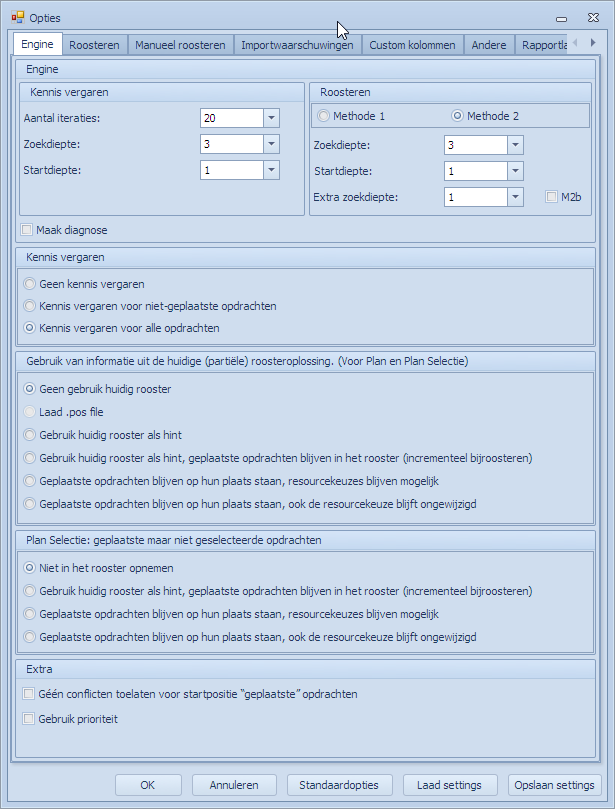
De opties worden hier getoond zoals ze standaard gezet worden (“Standaardopties”). Merk op dat men de standaardopties kan terugzetten door op de knop “Standaardopties” te drukken en dan te kiezen voor ofwel “Engine en Roosteren” ofwel voor “Manueel roosteren”. Andere optietabbladen worden hierdoor niet geraakt.
Inhoud
- Gebruik van informatie uit de huidige (partiële) roosteroplossing
- Plan selectie: geplaatste maar niet geselecteerde opdrachten
- Kennis vergaren
- Mogelijke combinaties van opties
- Extra | Geen conflicten toelaten voor startpositie Geplaatste opdrachten
- Extra | Gebruik prioriteit
- Engine | Kennis vergaren
- Engine | Roosteren
- Engine | Maak Diagnose
Gebruik van informatie uit de huidige (partiële) roosteroplossing
Deze opties zijn van toepassing voor “Plan” en “Plan selectie”, niet voor “Analyseer opdrachten”.
Hiermee bepalen we wat de MBE moet doen met de informatie die Mondriaan heeft over de huidige plaats in het rooster en de resourceskeuzes die gemaakt werden. Elke opdracht die geselecteerd wordt om naar de MBE te sturen, kan immers al geplaatst zijn. Ofwel doet de MBE niets met deze informatie, ofwel neemt de MBE deze informatie mee en wordt het enkel als hint gebruikt, ofwel wordt een deel of alles behouden.

Opties:
- Geen gebruik huidig rooster: de eventuele informatie die Mondriaan heeft over de plaats in het rooster en de resourcekeuzes die gemaakt werden, worden niet gebruikt door de MBE.
- Laad .pos file: (niet actief voor gebruikers): deze optie laat toe om informatie over de plaats in het rooster en de resourcekeuzes apart te laden in de MBE.
- Gebruik huidig rooster als hint: de informatie die Mondriaan heeft, wordt als hint meegegeven aan de MBE. De MBE zal die informatie gebruiken als eerste keuze wanneer hij een opdracht in het rooster tracht te plaatsen. Met deze optie kunnen eerder geplaatste opdrachten falen ten behoeve van de plaatsing van nog niet geplaatste opdrachten. Verder heeft dit geen effect.
- Gebruik huidig rooster als hint, geplaatste opdrachten blijven in het rooster (incrementeel bijroosteren): ook hier wordt de informatie van de geplaatste opdrachten door de MBE als hint gebruikt in de zoektocht naar een oplossing, met een belangrijk verschil: de geplaatste opdrachten kunnen nooit falen ten behoeve van opdrachten, die nog niet geplaatst waren en mee opgenomen werden in de selectie. Hierdoor verzekert men een blijvende oplossing voor de reeds geplaatste opdrachten en probeert men er de niet geplaatste bij te roosteren. Deze techniek noemt men ook “incrementeel bijroosteren”.
- Geplaatste opdrachten blijven op hun plaats staan, resourcekeuzes blijven mogelijk: dit is een verdere beperking van de vorige optie. De reeds geplaatste opdrachten kunnen niet meer van plaats wijzigen in het rooster, enkel de keuze van de resources blijft vrij voor de geplaatste opdrachten. Dit is ook een vorm van incrementeel bijroosteren maar strenger dan de vorige.
- Geplaatste opdrachten blijven op hun plaats staan, ook de resourcekeuze blijft ongewijzigd: een laatste beperking t.o.v. de vorige optie is dat het niet toegelaten wordt om de keuzeresources van de geplaatste opdrachten nog te wijzigen ten behoeve van de niet geplaatste opdrachten. Dit is de laatste vorm van incrementeel bijroosteren.
De standaardoptie is de eerste, waarbij we de informatie uit het huidig rooster niet gebruiken.
Plan selectie: geplaatste maar niet geselecteerde opdrachten
Deze opties zijn enkel van toepassing voor “Plan selectie”. Het gaat over geplaatste opdrachten die niet in de selectie opgenomen werden en dus niet naar de MBE zouden gaan. Opdrachten die niet mee in de selectie zitten, worden standaard als ongeplaatst gemarkeerd als Mondriaan het resultaat van de MBE inleest. Indien men dit wil vermijden, kan men dat doen via deze opties. Hier kan men bepalen of de niet geselecteerde, maar wel geplaatste, opdrachten mee naar de MBE gaan en wat de MBE moet/mag doen met deze opdrachten.
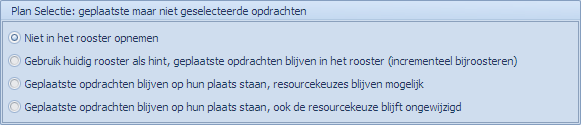
Opties:
- Niet in het rooster opnemen: de wel geplaatste, maar niet geselecteerde, opdrachten worden niet naar de MBE gestuurd en er wordt dan ook geen rekening mee gehouden tijdens het roosteren. Na het roosteren zullen ze niet langer geplaatst zijn.
- Gebruik huidig rooster als hint, geplaatste opdrachten blijven in het rooster (incrementeel bijroosteren): hier wordt de informatie van de geplaatste opdrachten door de MBE als hint gebruikt in de zoektocht naar een oplossing. Bijkomend wordt via deze optie een ander belangrijk aspect bepaald. De geplaatste opdrachten kunnen nooit falen ten behoeve van opdrachten, die nog niet geplaatst waren en mee opgenomen werden in de selectie. Hierdoor verzekert men een blijvende oplossing voor de reeds geplaatste opdrachten en probeert men er de niet geplaatste bij te roosteren. Deze techniek noemt men ook “incrementeel bijroosteren”.
- Geplaatste opdrachten blijven op hun plaats staan, resourcekeuzes blijven mogelijk: dit is een verdere beperking van de vorige optie. De reeds geplaatste opdrachten kunnen niet meer van plaats wijzigen in het rooster, enkel de keuze van de resources blijft vrij voor de geplaatste opdrachten. Dit is ook een vorm van incrementeel bijroosteren, maar strenger dan de vorige.
- Geplaatste opdrachten blijven op hun plaats staan, ook de resourcekeuze blijft ongewijzigd: een laatste beperking t.o.v. de vorige optie is het ook niet toelaten dat de keuzeresources van de geplaatste opdrachten nog wijzigen ten behoeve van de niet geplaatste opdrachten. Dit is de laatste vorm van incrementeel bijroosteren.
De standaardoptie is de eerste, waarbij de niet geselecteerde maar wel geplaatste opdrachten niet mee opgenomen worden voor de MBE planning.
Kennis vergaren
De MBE heeft er meestal baat bij om eerst een analyse te doen van de complexiteit van het probleem. Het bepalen van de complexiteit van de opdrachten, in de context van andere opdrachten en andere gestelde beperkingen, noemen we hier “kennis vergaren”.

Opties:
- Geen kennis vergaren: bij deze optie wordt geen kennis vergaard en gaat de MBE een oplossing zoeken zonder extra kennis over de complexiteit van de opdrachten.
- Kennis vergaren voor de niet-geplaatste opdrachten: bij deze optie wordt enkel de complexiteit bepaald van de geselecteerde maar niet-geplaatste opdrachten. De geplaatste opdrachten maken hier dan wel deel uit van de context waarbinnen kennis vergaard wordt voor de niet-geplaatste opdrachten.
- Kennis vergaren voor alle opdrachten: bij deze optie wordt kennis vergaard voor alle geselecteerde opdrachten.
De standaardoptie is de derde, waarbij steeds kennis vergaard wordt voor alle geselecteerde opdrachten.
Mogelijke combinaties van opties
Voor de optieblokken die tot nu toe besproken werden, zijn niet alle combinaties mogelijk. In deze sectie bespreken we de mogelijke combinaties. Het gaat hier om deze optieblokken:
- Kennis vergaren
- Gebruik van informatie uit de huidige (partiële) roosteroplossing. (Voor Plan en Plan selectie)
- Plan selectie: geplaatste maar niet geselecteerde opdrachten.
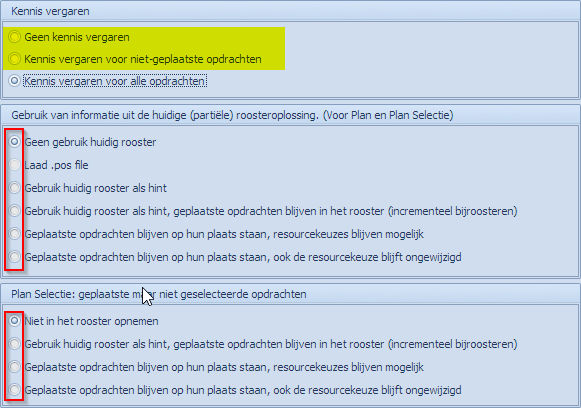 |
1ste optieblok:
Deze opties zijn combineerbaar met elk van de opties in de 2 andere blokken. Geen kennis vergaren is steeds een optie. Kennis vergaren van de niet geplaatste opdrachten kan ook steeds, onafhankelijk van het feit of men kennis van geplaatste opdrachten wenst te gebruiken. |
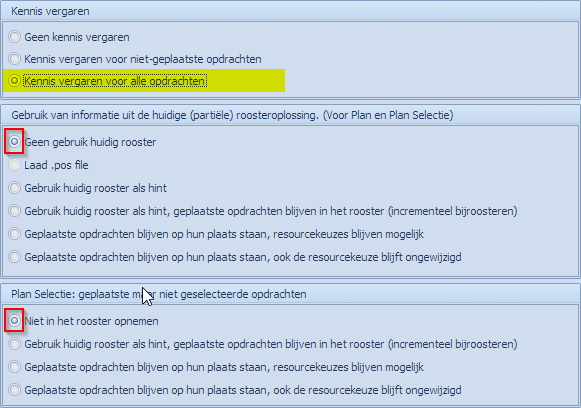 |
1ste optieblok:
Is enkel combineerbaar met de eerste optie van de andere blokken. Van zodra men informatie van de huidige plaatsing van opdrachten wenst te gebruiken, kan men geen kennis meer vergaren van de geplaatste opdrachten. Dus, als men informatie over de huidige plaatsing wenst te gebruiken, kan men enkel kennis vergaren voor de niet geplaatste opdrachten. |
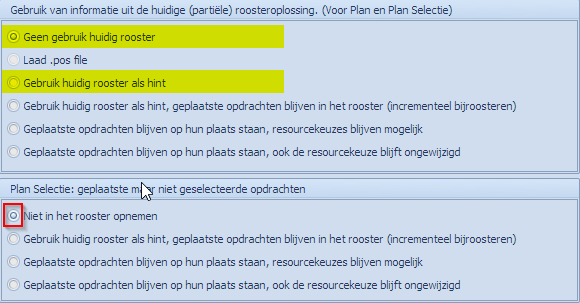 |
2de optieblok:
Kan enkel gecombineerd worden met “Niet in het rooster opnemen” van de geplaatste, maar niet geselecteerde, opdrachten. Dus, als men de niet geselecteerde (wel geplaatste) opdrachten als basis wil behouden (en incrementeel bijroosteren) dan moeten ook de geselecteerde opdrachten die geplaatst waren in die basis opgenomen worden. |
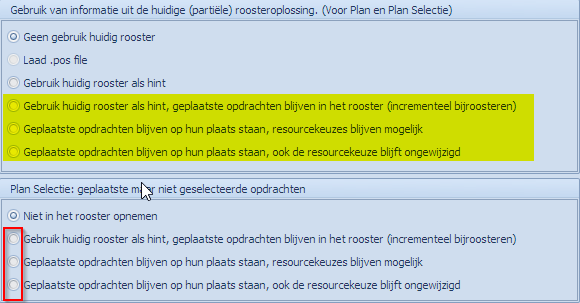 |
2de optieblok:
Deze opties zijn combineerbaar met elke van de 3 laatste opties van blok 3. |
De meest gebruikte combinaties zijn:
- Alles in een geheel normaal roosteren:
- Blok 1: Kennis vergaren voor alle opdrachten
- Blok 2: Geen gebruik huidig rooster
- Blok 3: Niet in rooster opnemen
- Incrementeel een deel bijroosteren:
- Blok 1: Kennis vergaren voor niet-geplaatste opdrachten
- Blok 2: Gebruik huidig rooster als hint, geplaatste opdrachten blijven in het rooster (incrementeel bijroosteren)
- Blok 3: Niet in rooster opnemen
Extra | Geen conflicten toelaten voor startpositie Geplaatste opdrachten
Onderaan in het optiescherm vindt men volgende optie:

Deze optie is van belang bij planactiviteiten waarbij men wenst te vertrekken van een deel reeds geplaatste opdrachten waarbij men een deel niet geplaatste opdrachten wenst bij te roosteren (incrementeel roosteren). Indien men bij dergelijke planactiviteit niet wenst dat er geplaatste opdrachten kunnen opgeofferd worden ten voordele van nog niet geplaatste opdrachten dan heeft men dit vangnet nodig.
Volgend voorbeeld moet dit verduidelijken. Stel dat men een rooster heeft dat didactisch in orde is en volledig geroosterd met leerkrachtwensen. Stel dat na inspectie van het rooster blijkt dat er toch nog wat leerkrachtwensen toegevoegd moeten worden. Als men deze nieuwe wensen aanmaakt, dan worden die wensen op een bepaalde plaats in de leerkrachtroosters geplaatst waarbij er mogelijk conflicten kunnen ontstaan. Ook de gebruiker zou die wens in het rooster een voorlopige plaats kunnen gegeven hebben, niet rekening houdend met mogelijke conflicten. Wensen en lesopdrachten conflicteren, maar zijn wel gemarkeerd als “geplaatst”. Bij incrementeel bijroosteren, met behoud van geplaatste opdrachten, gaat Mondriaan de geplaatste opdrachten doorgeven aan de MBE. Maar, de MBE aanvaardt geen conflicten. Echter, de bijgemaakte wensen staan in het rooster en hebben conflicten met lesopdrachten. Wat Mondriaan dan doet, is alle conflicterende opdrachten als NIET geplaatst doorgeven aan de MBE, en dit zonder onderscheid te maken tussen lesopdrachten, leerkrachtwensen, etc. Dus, de lesopdrachten die geplaatst waren en in conflict staan met geplaatste wensen, zullen opnieuw geroosterd worden met de kans dat ze opgeofferd worden ten voordele van een wens.
Om deze kans te vermijden kan men deze optie aanvinken. Als deze optie aangevinkt is, gaat Mondriaan de MBE niet opstarten als er conflicten bestaan tussen “geplaatste” opdrachten en waarbij gevraagd wordt om aan incrementeel roosteren te doen. De enige functie van deze optie is dus het tegenhouden van de planning als dergelijke situatie zich voordoet. Het is aan de gebruiker om te kiezen voor dit vangnet.
Verder is het aan de gebruiker om deze conflicten eerst te verwijderen. De gebruiker kan conflicten opsporen via de “Conflicten” knop. Dit geeft alle mogelijke conflicten, ook tussen lesopdrachten. Heeft men een conflict tussen bijvoorbeeld een (aantal) lesopdrachten en een wens dan kan men de wens gewoon uit de planning halen zodat hij als “niet geplaatst” wordt gemarkeerd voor hij de MBE ingaat.
Mondriaan heeft ook 2 acties voorzien om op een snelle manier conflicterende wensen en conflicterende optimalisatieopdrachten op “niet geplaatst” te zetten. Deze acties vindt men in:
- Tools | Plannen | Wis conflicterende wensen
- Tools | Plannen | Wis conflicterende optimalisaties
Met “Wis” wordt hier bedoeld dat ze uit de planning gehaald worden en dus als “niet geplaatst” naar de MBE zullen gaan.
Heeft men echter conflicten tussen lesopdrachten onderling dan gaat de gebruiker dit eerst manueel moeten oplossen (indien de optie aanstaat).
Extra | Gebruik prioriteit
Onderaan in het optiescherm vindt men volgende optie:

Voor de MBE is er tussen aangeboden opdrachten, die gepland moeten worden, normaal geen verschil in prioriteit. Alle opdrachten worden evenwaardig behandeld en elke opdracht heeft evenveel kans om geplaatst te worden of om te falen. In sommige uitzonderlijke gevallen kan het echter nuttig zijn om opdrachten in prioriteitscategoriëen in te delen. De gebruiker kan dat doen door in het Opdrachten tabblad (en ook in het Wensen tabblad) de kolom “Prioriteit” te gebruiken en daar via een getal een prioriteit op te geven. Alle opdrachten en wensen die dezelfde prioriteit hebben, worden gelijkwaardig behandeld. Een opdrachtcategorie met een hogere prioriteit (hogere prioriteit = lager nummer in Prioriteit kolom. 0 is hoogste prioriteit) heeft voorrang op een opdrachtcategorie met een lagere prioriteit. Dus, de opdrachten met Prioriteit 0 worden eerst geplaatst, dan komen de opdrachten met prioriteit 1, enz. Opdrachten met prioriteit 1 kunnen nog wel verplaatsingen veroorzaken van de opdrachten met prioriteit 0, maar kunnen er nooit voor zorgen dat een opdracht van prioriteit 0 faalt. Merk op dat opdrachten zonder prioriteit met de laagste prioriteit behandeld worden.
In feite komt het werken met prioriteiten er op neer dat de MBE telkens de volgende set van opdrachten incrementeel bijroostert maar dan op een automatische manier. Hier heeft de gebruiker geen invloed op de roosterparameters (methode, diepte, etc) die voor elke categorie gebruikt wordt. Het zijn voor elke categorie dezelfde parameters.
Merk ook op dat het falen van een opdracht met een hogere prioriteit niet belet dat de MBE aan de volgende categorie van opdrachten begint.
Het gebruiken van veel verschillende prioriteiten heeft geen zin. Het gebruik van 2 tot 4 prioriteiten is zeker mogelijk, maar als men veel hoger gaat dan zal men ook zien dat de MBE niet meer de volledige flexibiliteit heeft om een oplossing voor het geheel te vinden, zeker niet voor “Methode 2” (zie verder).
Engine | Kennis vergaren
Naast de beslissing of er al dan niet kennis vergaard moet worden en voor welke opdrachten, kan de gebruiker ook bepaalde parameters zetten, die bepalen hoe grondig de analyse van de complexiteit gedaan moet worden. Met grondig wordt hier dan vooral bedoeld hoeveel moeite de MBE moet doen om een idee te krijgen van de complexiteit van elke opdracht binnen de context van de andere opdrachten en gestelde beperkingen. Na het bepalen van de complexiteit start de MBE met het echte zoekwerk naar een oplossing en kan hij bij die zoektocht gebruik maken van de kennis over die complexiteit. Het vergaren van kennis geeft geen 100% garantie op een snellere oplossing, maar het is zeker nuttig om dit te doen. De MBE (“Mondriaan Backtrack Engine”) maakt gebruik van recursieve backtrack algoritmes. Deze worden zowel gebruikt voor het vergaren van kennis als voor het roosteren. Omdat het kennis vergaren en het roosteren gebruik maken van dezelfde algoritmes, kan men voor beide gevallen via parameters invloed hebben op deze algoritmes. De linkerkant van dit scherm toont de parameters die we kunnen zetten voor het kennis vergaren. Er zijn soorten algoritmes, “Methode 1” en “Methode 2”. Omdat we voor kennis vergaren enkel “Methode 1” gebruiken, kan er voor kennis vergaren geen keuze gemaakt worden. Bij het roosteren kan dat wel.
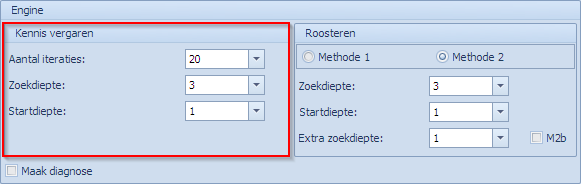
Er zijn 3 parameters die de gebruiker kan instellen (voor “Methode 1” binnen kennis vergaren) en die momenteel getoond worden zoals ze standaard ingesteld worden.
- Aantal iteraties: kennis vergaren wordt in iteraties uitgevoerd. Bij elke iteratie worden de opdrachten in een andere context bekeken en wordt er de complexiteit van bepaald. Van alle iteraties wordt de gemiddelde complexiteit bepaald. Echt moeilijke opdrachten komen dan bovendrijven. Een goede standaard blijkt een 20-tal iteraties te zijn. Als uit experimenten met een specifiek probleem blijkt dat het ook met minder kan of met meer moet, dan kan dat zeker aangepast worden.
- Zoekdiepte: het MBE algoritme (hier “Methode 1”) maakt gebruik van backtracktechnieken. De zoekdiepte bepaalt hoe diep gegaan mag worden in “het verplaatsen” van opdrachten ten voordele van “het plaatsen” van een te plaatsen opdracht X. Is de zoekdiepte bijvoorbeeld 3 dan mag om X te plaatsen Y verplaatst worden, om Y te plaatsen Z verplaatst worden en om Z te plaatsen Q verplaatst worden. Maar Q moet dan een vrije plaats vinden want voor Q mag niets meer verplaatst worden. Standaard zetten we de zoekdiepte op 3 en dat is in de meeste gevallen goed. Voor iets complexere gevallen is 4 nodig maar 5 komt zelden voor.
- Startdiepte: via deze parameter bepaalt men of men eerst eerder in de breedte zoekt, of meteen in de diepte. Standaard zetten we de startdiepte op 1. Dit wil zeggen dat we in een eerste stap kijken of we voor X geen oplossing kunnen vinden op een roosterpunt waar geen enkele opdracht moet wijken. Als dat niet lukt verhogen we de diepte tot we aan de ingestelde zoekdiepte zitten.
Merk op dat de standaardinstellingen voor Zoekdiepte en Startdiepte gelijk zijn voor “Kennis vergaren” en “Roosteren”. Het is gebleken dat de snelste oplossing vaak bekomen wordt door deze instellingen inderdaad in lijn te houden. De gebruiker heeft de uiteindelijke keuze.
Engine | Roosteren
Naast de beslissing voor welke opdrachten er een oplossing gezocht moet worden, kan de gebruiker ook sturing geven aan de algoritmes die gebruikt worden. Er zijn 2 backtrack algoritmes waaruit de gebruiker kan kiezen. Het eerste algoritme (“Methode 1”) werd al aangehaald bij “Engine | Kennis vergaren” en wordt uitzonderlijk ook gebruikt bij het roosteren (bij bepaalde technieken die op een andere plaats uitgelegd worden). Meestal wordt een andere versie van het algoritme gebruikt (“Methode 2”) voor het effectieve roosteren.
- Methode 1: zelfde als bij “kennis vergaren”. Wordt meestal niet gebruikt omdat het voor het roosteren te beperkt is. Wel bij sommige roostertechnieken, zoals bij incrementeel roosteren, kan het soms nuttig zijn om op een dieper niveau een beperkt aantal opdrachten bij te roosteren.
- Methode 2: de standaardoptie voor het Roosteren. Het grote voordeel van deze methode is dat er veel verder gezocht wordt dan met het eenvoudig recursief in de breedte en diepte zoeken van Methode 1. Het zou ons te ver leiden om die technieken hier uit te leggen maar in de kern maakt Methode 2 zelf ook gebruik van Methode 1. Vandaar dat men ook voor Methode 2 de parameters Zoekdiepte en Startdiepte ziet.
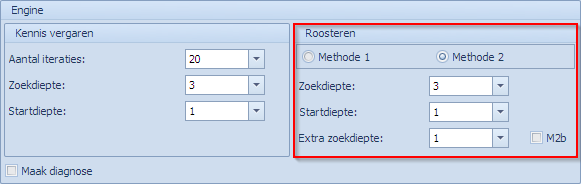
Er zijn 4 parameters die de gebruiker kan instellen (de eerste 2 voor “Methode 1” en “Methode 2”, de laatste twee zijn enkel nuttig voor “Methode 2”) en die momenteel getoond worden zoals ze standaard ingesteld worden.
- Zoekdiepte: (M1 en M2) Zie beschrijving bij “Engine | Kennis vergaren”
- Startdiepte: (M1 en M2) Zie beschrijving bij “Engine | Kennis vergaren”
- Extra Zoekdiepte: (M2). Zoals uitgelegd maakt het M2 algoritme ook gebruik van het M1 algoritme maar heeft er als het ware een laag rond gebouwd. De parameters “Zoekdiepte” en “Startdiepte” hebben dus voor M1 en M2 dezelfde betekenis en dienen in beide gevallen voor het sturen van algoritme van M1. Als de extra laag die M2 rond M1 gebouwd heeft, merkt dat een bepaalde opdracht X ook niet geplaatst kan worden via de extra intelligentie die M2 aan M1 toevoegt, dan kunnen we overgaan tot het individueel toekennen van toch een hogere zoekdiepte voor de gefaalde opdracht X. Standaard wordt die extra bonusdiepte op 1 gezet. Indien X een eerste keer faalt met M2 dan wordt de opgegeven zoekdiepte voor X met één verhoogd en krijgt X een tweede kans. Men kan deze parameter ook op bijvoorbeeld 2 zetten. Dit laat dan toe om voor X de zoekdiepte in 2 stappen te verhogen. In een eerste stap Zoekdiepte+1, indien geen oplossing gevonden naar Zoekdiepte+2. Als X dan ook via deze individuele verhoging van de zoekdiepte niet opgelost kan worden, dan faalt X finaal. De standaardwaarde voor “Extra zoekdiepte” is dus 1 en dat is in 99% van de gevallen voldoende.
- M2b: dit is een vlagje dat standaard uitgevinkt is. M2b slaat op een b-versie van Methode 2. Standaard staat dus de a-versie actief. Vanaf versie BT20.00.02 van de MBE is deze gewijzigde versie van Methode 2 beschikbaar. De b-versie van Methode 2 zorgt ervoor dat het algoritme op een meer conservatieve manier de kaarten herschudt tijdens het niet kunnen oplossen van lokale problemen (een cluster van lastige opdrachten). Als men in de a-versie ziet dat tijdens het verloop van het roosteren er extreem veel falingen van dezelfde opdrachten voorkomen (jump-factoren gaan de hoogte in) dan is het waarschijnlijk goed om eens te kijken of de b-versie het niet beter doet. Er zijn heel wat voorbeelden waarbij het verschil tussen de a-versie en de b-versie spectaculair is. Opnieuw is het aan de gebruiker om te bepalen wat voor zijn roosterprobleem de beste oplossing is.
Voor al deze parameters geldt dat er omzichtig mee omgesprongen moet worden. Het te snel verhogen van de zoekdiepte of extra zoekdiepte kan al snel leiden tot onnodige lange rekentijden van het algoritme. Indien problemen moeilijk oplosbaar zijn, moet er een (door Mondriaan ondersteunde) analyse gebeuren om de knelpunten (of onoplosbaarheden) te vinden. Het is vaak interessant om op minder hoge dieptes te roosteren om snel een zicht te krijgen op probleemgevallen.
Engine | Maak Diagnose
Deze optie is van toepassing op “Plan” en “Plan selectie”. Als deze optie aangevinkt is, dan gaat de MBE een diagnosebestand aanmaken over de opdrachten en resources die in het spel zijn.
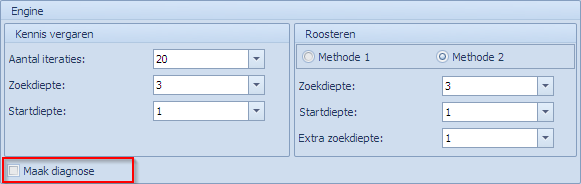
Indien men de optie “Maak diagnose” aanvinkt en men doet vervolgens een “Plan” of “Plan selectie”, dan komt er een extra knop tevoorschijn in de popup die verschijnt als de MBE afgelopen is.
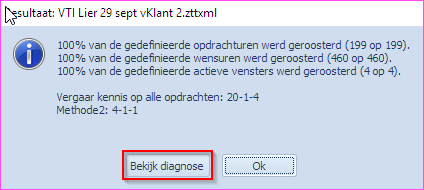
Drukt men op “Bekijk diagnose” dan opent volgend “txt” bestand waarin men de gevraagde diagnose kan vinden. Merk op dat je geen toegang meer hebt tot het Mondriaan scherm zolang dit tekstbestand open staat.
De diagnose gebeurt met dezelfde instellingen als die voor de planning voorzien werden.
Het moment waarop de diagnose gebeurt
Indien men “Plan” of “Plan selectie” doet, dan kan afhankelijk van de MBE opties al dan niet kennis vergaard worden en al dan niet geroosterd worden. In elk van de mogelijke gevallen wordt de diagnose als laatste stap uitgevoerd. Op die manier kan zowel de mogelijks vergaarde kennis als de mogelijke plaatsing van de opdrachten in rekening gebracht worden voor de diagnose.
Meer uitleg over de inhoud van het diagnosebestand kan men vinden op volgende pagina:
